Hoe UGent-onderzoekers ‘dialect in het wild’ bestuderen
Taalkundigen van de Gentse universiteit hebben iets unieks in huis: honderden uren opnames van dialectsprekers uit Vlaanderen en Noord-Frankrijk, verzameld sinds de jaren 1960. Die audioschat is nu toegankelijk via een digitale database, waardoor wetenschappers er makkelijker mee aan de slag kunnen. In dit artikel leggen de huidige onderzoekers uit hoe deze collectie van ‘stemmen uit het verleden’ tot stand is gekomen.
De afdeling Nederlands van de vakgroep Taalkunde aan de Universiteit Gent heeft een lange traditie van dialectologisch onderzoek, waardoor er in de loop der eeuwen rijke verzamelingen met dialectgegevens tot stand zijn gekomen.
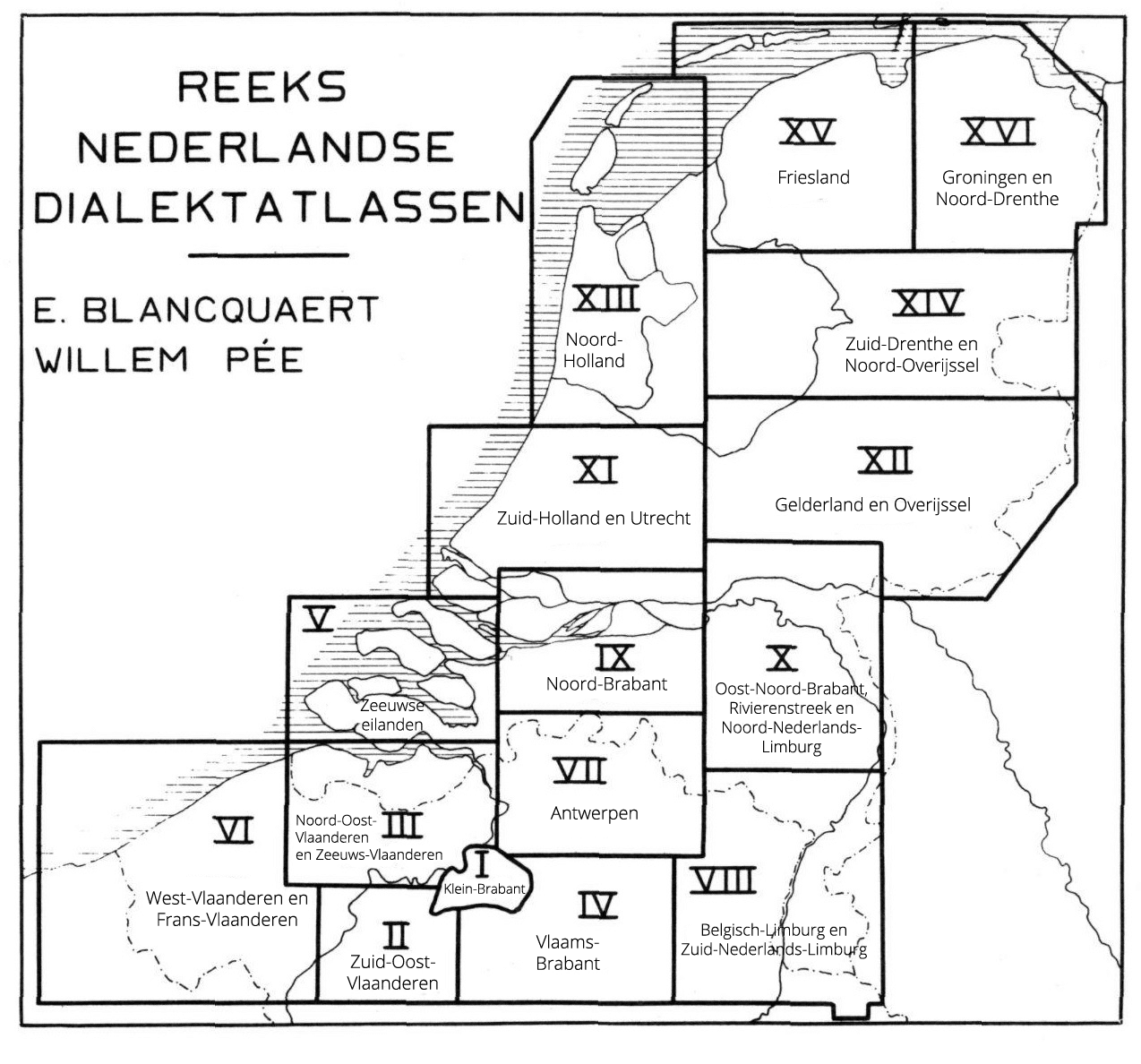
Tot de jaren vijftig van de vorige eeuw waren die verzamelingen vooral schriftelijk van aard: zegslieden werden gevraagd hoe ze bepaalde woorden of zinnen in hun dialect zouden zeggen, en een onderzoeker pende hun antwoorden neer. Veel van dat schriftelijke UGent-materiaal is vandaag al gedigitaliseerd. Zo kun je de duizenden fonetisch neergeschreven dialectzinnen van de Reeks Nederlandse Dialectatlassen vandaag online bekijken en gedeeltelijk doorzoeken. Ook het Woordenboek van de Vlaamse Dialecten is intussen digitaal raadpleegbaar.
 Dialectbanden uit de collectie van de UGent
Dialectbanden uit de collectie van de UGent© UGent
Vanaf de jaren zestig – toen de bandopnemer een populair en betaalbaar instrument was geworden – werd het mogelijk om gesproken dialect te registreren. Een groot voordeel van opnames is dat je gemakkelijker spontane taal kan betrappen en zo “dialect in het wild” kunt bestuderen. In die context werd er vanaf de jaren zestig aan de Universiteit Gent een unieke audiocollectie opgebouwd waarin de stemmen van honderden twintigste-eeuwse dialectsprekers uit Vlaanderen en Noord-Frankrijk geregistreerd werden voor het nageslacht. Die collectie werd lange tijd weinig gebruikt; een nadeel van geluidsopnames is immers dat er heel wat werk verzet moet worden (en er dus ook een stevige financiële investering nodig is) voor ze bruikbaar zijn voor wetenschappelijk onderzoek. Daar kwam een aantal jaar geleden gelukkig verandering in, toen een aantal taalwetenschappers aan de UGent de handen in elkaar sloeg om de stemmen uit het verleden opnieuw te doen spreken, via het zogenoemde Gesproken Corpus van de zuidelijk-Nederlandse Dialecten, afgekort als GCND (de taalkundige term corpus verwijst naar een “systematische verzameling teksten voor linguïstisch onderzoek”).
Stemmen uit het verleden
In de jaren zestig van de vorige eeuw begon op initiatief van professor Valeer Frits Vanacker een groot project om álle plaatselijke dialecten van Nederlandstalig België en Frans-Vlaanderen (en naderhand ook Zeeuws-Vlaanderen) op band te registreren. Het was de bedoeling om een zeer dialectvaste zegsman of zegsvrouw in een spontaan gesprek aan het woord te laten, gedurende een achtenveertigtal minuten, want dat was de lengte van een band op de Revox-bandopnemers die werden gebruikt. Men hoopte binnen die tijd de belangrijkste fonologische verschijnselen van een bepaalde plaats te kunnen documenteren. Vanacker, een van de grondleggers van de studie van dialectsyntaxis in de Nederlanden, hoopte daarnaast ook syntactische verschijnselen in de spontane taal te kunnen bestuderen. Zinsbouw is – in tegenstelling tot woordenschat – immers moeilijker via vragenlijsten te bevragen. Bovendien bieden opnames van spontane taal de mogelijkheid na te gaan in welke verhouding concurrerende structuren gebruikt worden.
 Valeer Frits Vanacker was een van de grondleggers van de studie van dialectsyntaxis in de Nederlanden
Valeer Frits Vanacker was een van de grondleggers van de studie van dialectsyntaxis in de NederlandenDe informant moest aan een aantal criteria voldoen. Niet alleen zocht men goede vertellers, de deelnemers waren bij voorkeur ook bejaard en laaggeschoold. In de jaren zestig en zeventig van de vorige eeuw was men er immers achter gekomen dat de verhoogde scholingsgraad van de bevolking, de invloed van de media (krant, radio en tv) en de verhoogde sociale en geografische mobiliteit de voorouderlijke dialecten zouden doen veranderen of verdwijnen. Daarnaast moesten beide ouders en partner van dezelfde gemeente afkomstig zijn en mocht de spreker zijn gemeente zo weinig mogelijk verlaten hebben. Door die criteria kwamen de onderzoekers op het platteland veelal terecht bij de boerenbevolking en in de steden bij de arbeidersklasse. Het was een mensentype dat vandaag de dag zeer zeldzaam is geworden: iemand die gewoonweg geen ander taalregister had dan zijn plaatselijke dialect. Iemand die in de jaren 1960 en ’70 pakweg tachtig jaar was, is geboren rond 1880, dus ongeveer dertig jaar vóór de invoering van de leerplicht in 1914 (althans in België).
De onderzoekers kwamen veelal terecht bij de boerenbevolking en bij de arbeidersklasse. Het was een mensentype dat vandaag de dag zeer zeldzaam is geworden: iemand die gewoonweg geen ander taalregister had dan zijn plaatselijke dialect
Om het gesprek zo spontaan mogelijk te laten verlopen, werden de opnames gemaakt bij de sprekers thuis en werd er gewerkt met een tussenpersoon, die de informant niet alleen kende en hem meestal ook had aangebracht, maar die het gesprek ook leidde, terwijl een technicus (vaak de onderzoeker zelf) zich in een andere kamer om de apparatuur bekommerde. Op die manier werd de zogenoemde observator’s paradox vermeden: de omstandigheid dat een onderzoeker in zijn zoektocht naar spontaan taalmateriaal de spontaneïteit net verstoort door zijn aanwezigheid. De thuisopnames hadden wel als nadeel dat het gesprek vaak verstoord werd door achtergrondgeluiden zoals tikkende klokken, rammelende kookpotten of de hond des huizes.
De allereerste opname uit de collectie werd gemaakt in Dikkebus op 29 maart 1961. De collectie groeide in het begin maar traag: er waren weinig fondsen om de reiskosten te vergoeden en de professoren moesten vaak aanwezig zijn op de universiteit. Bovendien hadden veel “ideale” sprekers, met name de boeren, in de zomermaanden geen tijd om te praten omdat ze op het veld moesten werken. Toch zijn er uiteindelijk 783 geluidsbanden opgenomen voor 550 verschillende plaatsen. Dat betekent dat er op sommige plaatsen meerdere opnames gemaakt werden. Dat gebeurde als ze in het kader van een licentieverhandeling werden gemaakt, omdat de studenten vaak onderzoek deden naar de taal van meerdere generaties en dus opnames maakten bij sprekers van verschillende leeftijden. Sommige sprekers kwamen uit dorpen of gehuchten die vandaag niet meer bestaan, zoals de verdwenen polderdorpen Lillo, Oorderen en Wilmarsdonk die in de jaren zestig plaats moesten maken voor de uitbreiding van de Antwerpse haven.
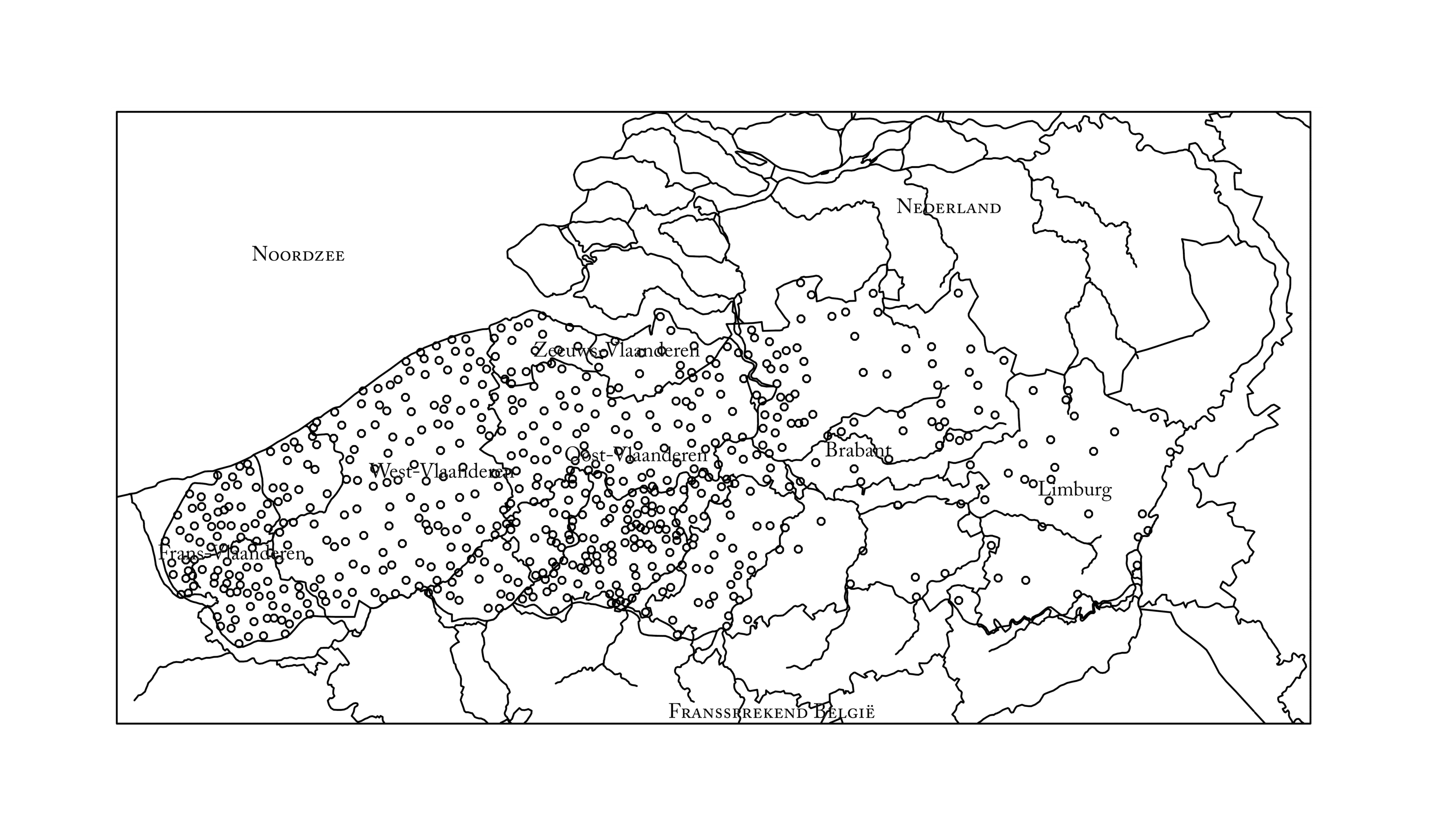
Bekijk je de spreiding van de banden op kaart, dan zie je dat Oost- en West-Vlaanderen het sterkst vertegenwoordigd zijn in de collectie. Vaak rekruteerden de Gentse onderzoekers immers hun studenten Nederlands als tussenpersoon en niet geheel toevallig telde de Gentse studentenpopulatie vooral West- en Oost-Vlamingen. Voor Frans-Vlaanderen werd een extra inspanning geleverd om in élk dorp waar nog Nederlands werd gesproken een opname te verwezenlijken, vanuit de veronderstelling dat het Vlaamse dialect het in dat gebied niet lang meer zou uithouden (het Musée de Flandre in Cassel ontving een kopie van de digitale versie van de Frans-Vlaamse opnames). Voor Zeeuws-Vlaanderen zette professor Johan Taeldeman zich in om zo veel mogelijk opnames te maken.
De collectie laat niet enkel de traditionele dialecten weerklinken, maar is ook de grootste verzameling levensverhalen van laaggeletterde twintigste-eeuwse Vlamingen
Het gespreksonderwerp was in principe helemaal vrij, maar werd in de praktijk wel wat gestuurd. Boeren werden uitgenodigd om het te hebben over de vroegere landbouwtechnieken, zeldzaam geworden beroepsmensen (mandenmaker, kuiper…) vertelden over hun beroep, veteranen hadden het over de Eerste en Tweede Wereldoorlog, vele informanten hadden de introductie van fiets, auto, radio, elektriciteit, tv enz. nog meegemaakt… De collectie laat dus niet enkel de traditionele dialecten weerklinken, maar is ook de grootste verzameling levensverhalen van laaggeletterde twintigste-eeuwse Vlamingen. Door hun unieke getuigenissen over het leven van toen is de collectie niet alleen taalkundig, maar ook volkskundig heel waardevol.
Digitalisering en ontsluiting
Het spreekt vanzelf dat er in de huidige digitale tijd nieuwe kansen liggen om de verzameling efficiënt te ontsluiten. De digitalisering van de bandopnames werd al aangevat in het begin van de eenentwintigste eeuw onder leiding van professor Taeldeman; alle geluidsfragmenten werden vervolgens ter beschikking gesteld op de website www.dialectloket.be (een initiatief van professor Jacques Van Keymeulen, met dank aan ererector Paul Van Cauwenberge, die in 2009 bemiddelde voor financiering).
Om de collectie maximaal te ontsluiten, is echter meer nodig dan digitalisering alleen; taalwetenschappers en volkskundigen moeten gericht kunnen zoeken naar specifieke woorden, zinsstructuren of thema’s zonder alle banden afzonderlijk te moeten beluisteren. Om dat mogelijk te maken, moeten de banden getranscribeerd worden. De eerste stappen daartoe werden al gezet in de jaren zestig en zeventig van de vorige eeuw, toen studenten transcripties maakten voor een deel van de opnames (318 in totaal) – op basis van een heel primitief transcriptieprotocol.
Dankzij financiering van verschillende kanalen (details onderaan bij dit stuk) werd er in 2019 een project opgestart dat niet alleen beoogt de volledige verzameling op een uniforme manier te transcriberen, maar ook de gaten in de collectie te dichten. Om dat laatste doel te bereiken, werden nieuwe opnames gemaakt in Vlaams-Brabant en Limburg, al was het niet vanzelfsprekend nog zegslieden te vinden die aan de oorspronkelijke selectiecriteria voldeden. Daarnaast werd ook samengewerkt met het Meertens Instituut in Amsterdam, dat geluidsopnames van Zeeuwse, Noord-Brabantse en Limburgse dialecten uit de Nederlandse Dialectenbank ter beschikking stelde. Door die samenwerking kon een database – of een corpus zoals dat in de taalkunde heet – gecreëerd worden die het hele zuidelijk-Nederlandse dialectgebied documenteert.
Door de samenwerking met het Meertens Instituut in Amsterdam kon een database worden gecreëerd die het hele zuidelijk-Nederlandse dialectgebied documenteert
De transcriptie van de samengebrachte opnames gebeurt voorlopig nog volledig manueel. Bij de aanvang van het project stond de ontwikkeling van automatische spraakherkenners voor gesproken dialecten nog niet ver genoeg om de transcriptie van de opnames (semi-)automatisch te laten gebeuren. Maar in de laatste jaren is er significante vooruitgang geboekt op gebied van automatische spraakherkenning. Daarom werkt het projectteam momenteel samen met taaltechnologen van de Universiteit Leuven om na te gaan of het transcriptieproces via spraakherkenning versneld kan worden.
De manuele transcriptie gebeurt op twee niveaus: een transcriptielaag die dicht bij het dialect blijft en een laag die meer bij het Standaardnederlands aanleunt. Die laatste transcriptielaag is onder andere nodig om de digitale teksten te ontsluiten voor onderzoekers die het dialect niet machtig zijn. De transcripties worden gemaakt met het opensourceprogramma ELAN en gealigneerd met het geluid, zodat controle steeds mogelijk blijft. Het mag duidelijk zijn dat een dergelijke manier van werken tijdrovend is: een transcribent heeft gemiddeld een uur tijd nodig om 200 seconden dialectgeluid te verwerken.
De transcribenten zijn – behalve voor de Frans-Vlaamse banden – jobstudenten, die twee soorten problemen moesten zien te overwinnen: in de eerste plaats begrijpen ze de zeer archaïsche dialecten niet altijd even goed (zelfs al beschouwen ze zichzelf nog als dialectsprekers), en bovendien zijn ze vaak vervreemd van de leefwereld van de zegslieden. Elke transcriptie wordt daarom nagelezen door oudere dialectvaardige vrijwilligers.
Om de collectie niet alleen op woordniveau doorzoekbaar te maken, maar ook op vlak van abstractere zinsstructuren, worden de transcripties in een tweede fase taalkundig verrijkt door het toevoegen van annotaties van woordsoorten (part-of-speech-tagging) en syntaxis (parsing). Zegt een spreker bijvoorbeeld “ik kom!”, dan wordt aan dat stukje transcriptie toegevoegd dat het om een opvolging van een voornaamwoord en een werkwoord gaat, die op syntactisch niveau functioneren als respectievelijk onderwerp en hoofd van de zin. De transcriptie “naar het Nederlands toe” maakt het mogelijk om dat in eerste instantie automatisch te laten doen door software die voor het Standaardnederlands bestaat – specifieke tools getraind op dialectmateriaal zijn er (nog) niet. Achteraf is echter nog heel wat manuele controle nodig.
Om het GCND ook inhoudelijk te ontsluiten voor volkskundig onderzoek maakten vrijwilligers samenvattingen van elke geluidsopname (zie www.dialectloket.be). Recent werden de opnames dankzij kredieten van de UGent verder thematisch geannoteerd met behulp van een uniforme trefwoorden-thesaurus, zodat de opnames thematisch geselecteerd en doorzocht kunnen worden. Zoek je op Dialectloket bijvoorbeeld ‘Wereldoorlog II’, dan kun je meteen de passages beluisteren waarin dat onderwerp besproken wordt; je hoeft niet langer de hele band door te nemen.
Het ontsluiten van de verzameling, zowel taalkundig als inhoudelijk, is een tijdrovend werk, maar het werpt zijn vruchten af. Sinds 24 oktober 2024 is de collectie taalkundig doorzoekbaar via de website van het Instituut voor de Nederlandse Taal (INT) in Leiden, dat instaat voor de hosting. De INT-applicatie mikt in eerste instantie op onderzoekers die de collectie taalkundig willen analyseren via een batterij aan zoekmogelijkheden, al kunnen ook geïnteresseerden die niet aan een onderzoeksinstelling verbonden zijn, toegang aanvragen. Wil je de opnames echter vooral beluisteren (met de transcripties als ondertitels erbij) of passages over specifieke thema’s opsporen, dan kun je terecht op de openlijk toegankelijke website www.dialectloket.be. Goed nieuws is ook dat het GCND-team het project dankzij aanvullende financiering naar de rest van Nederland zal uitbreiden. In de toekomst zullen in het corpus dus dialectstemmen uit het hele Europees-Nederlandse taalgebied weerklinken.
De volledige financiering van het project kwam tot stand via volgende kanalen:
2020-2024: FWO Middelzware onderzoeksinfrastructuur I.0.101.20N
2018-2020: FWO Navorserskrediet 1.5.310.18N aan A. Breitbarth (pilootproject)
2018-2021: FWO Postdoctoraal mandaat junior 1.2.P79.19N aan M. Farasyn (Frans-Vlaamse opnames)
2021-2024: FWO Postdoctoraal mandaat senior 1.2.P79.22N aan M. Farasyn (Frans-Vlaamse opnames)
2019-2021: Subsidies provincies Zeeland, West-Vlaanderen en Oost-Vlaanderen (pilootproject)




Geef een reactie
Je moet ingelogd zijn op om een reactie te plaatsen.